The Open GLAM Survey tracks open access activity at all scales, ranging from a historical centre’s single CC0 image published to Wikimedia Commons, to a national archive’s publication of millions of images on Europeana.
While GLAM is typically used to refer to Galleries, Libraries, Archives, and Museums, this term is imperfect and underinclusive. This Survey uses GLAM as shorthand to refer to any cultural or governmental organisation publishing digital collections using public domain tools or open licences.
Data collection primarily involves quantitative and qualitative research across GLAM websites, data aggregators, third party platforms, literature reviews, and information circulated among the open GLAM community. In addition to desk-based research, the Survey has gained much from the contributions of open culture enthusiasts, heritage professionals, and Wikipedians.
Each instance (i.e., institution or organisation) and policy is manually reviewed by the researchers to ensure digital collections and policies meet international standards for “open.” The result is a reliable, comprehensive survey of the global open GLAM community on open access programmes around the world that support new research, learning, and creativity.
The Survey is constantly growing as new GLAMs are identified and verified as meeting the criteria for inclusion. This means that the Survey includes all known examples of open GLAM policy and practice. It is by no means exhaustive. Indeed there are clear representation gaps in the data, which in themselves are important to document and highlight, as shown in the map below.
Stronger open GLAM representation correlates to more consistent legal authority, particularly for organisations that publish digitised collections to the public domain, in greater volumes, and at higher qualities. Other variations can be attributed to factors such as Western-centric concepts of museums and intellectual property, national recognition of Indigenous rights or data sovereignty, histoires of colonisation, socio-economic disparities, uneven levels of funding, and access to digital technologies.
You can find information on how to suggest new institutions for the Survey on the Submit an Entry page.
Surveyed instances of Open GLAM
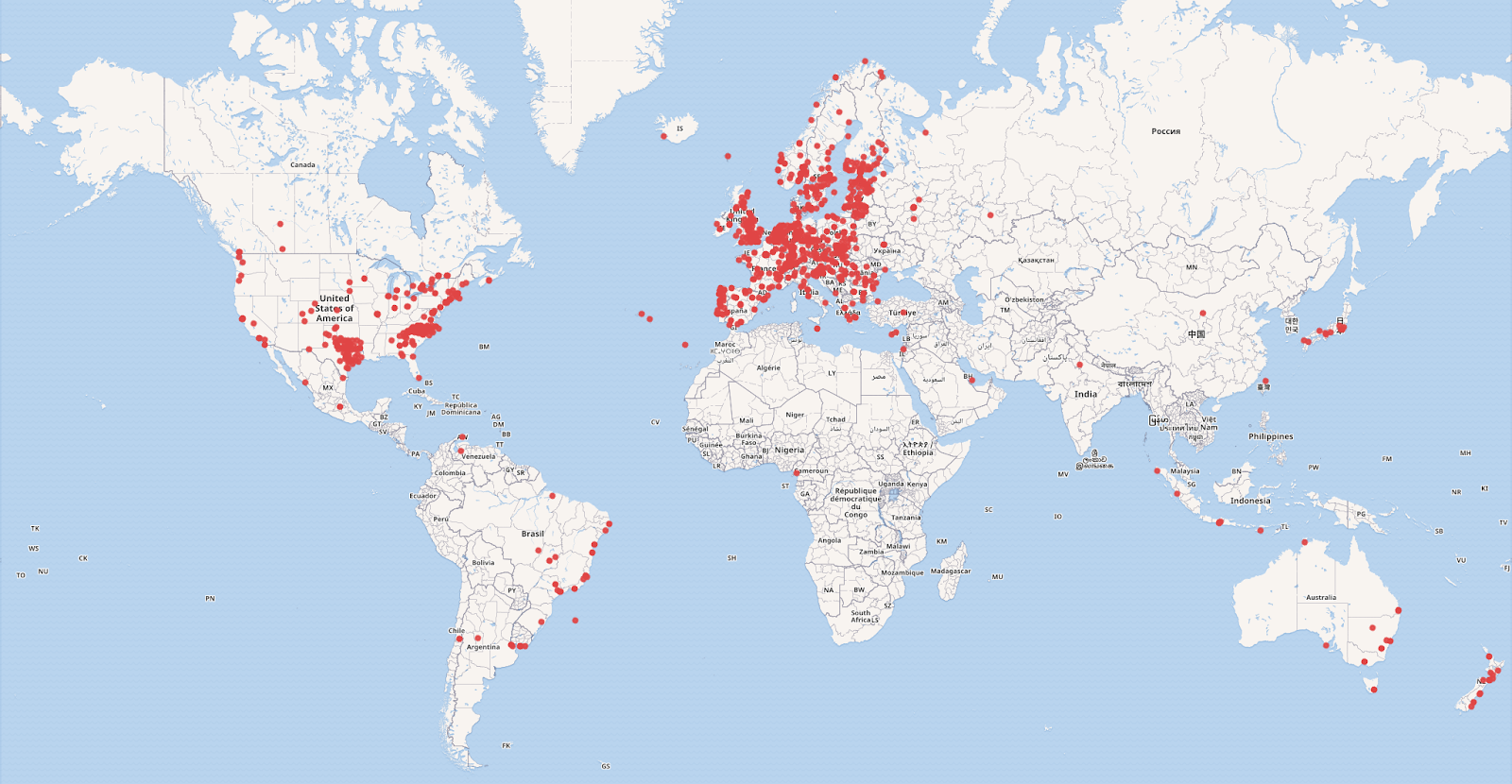
Surveyed instances of Open GLAM, May 2024
Data Structure
You can download the dataset by clicking on the “Download Data” link on the Survey page.
Data Fields and Descriptions
| Field | Description |
|---|---|
| Country | Full English language name of the country of the organisation’s location |
| Name | Official name of the organisation in the source language |
| ENG | Name in English for accessibility and data verification purposes |
| Part of | If part of a group of institutions |
| Type | Aggregator, Archive, Corporation, Gallery, Government, Library, Museum, Other, Private Collection, Repository, Research Institution, University, Visitor Attraction |
| Website | URL |
| Wikidata | URL |
| ENG Wikipedia | URL |
| Admission (if Gallery or Museum) | Free, Paid, Temporarily closed, Permanently closed, Information needed |
| First Open Access Instance | Date, if known |
| >Source | URL to information about the organisation’s first instance of open access, if available, also saved to the Internet Archive’s Wayback Machine |
| Open Access Scope (see note) | Some eligible data, All eligible data |
| Open Access Policy | URL to the organisation’s policy or webpage that includes the terms of open access, where available |
| TK & TCE Policy | URL to the organisation’s policy on the management of intellectual property in relation to traditional knowledge (TK) and traditional cultural expressions (TCE), where available |
| Metadata | Defined list of machine-readable statements (see note) |
| > Source | URL |
| Compliance (see note) | Public Domain, Disclaimer, Open |
| Total | Total number of open digital surrogates published by the organisation |
| Platform | Aggregator, Art UK, Coding Da Vinci, Europeana, Flickr, Flickr Commons, German Digital Library, Internet Archive, Japan Search, Own Website, Sketchfab, Trove, Wikimedia Commons |
| > Source | URL to the organisation’s open digital surrogates on the platform |
| Volume | The number of open digital surrogates published to the platform |
| Statement A | Defined list of machine-readable statements |
| Statement B | Defined list of machine-readable statements |
| Statement C | Defined list of machine-readable statements |
| API | URL of the organisation’s Application Programming Interface (API), where available |
| GitHub | URL of the organisation’s GitHub, where available |
Open Access Scope
Assigned by the researchers according to whether an open policy is applied to all eligible collections (i.e., public domain works) or to only a portion of eligible collections.
All eligible data indicates an organisation has released all digital surrogates of public domain works under public domain tools or open licences. For ‘All eligible data’ to be assigned, the organisation must include a clear statement indicating this in their open access policy.
Some eligible data indicates an organisation has released one or more digital surrogates of public domain works using public domain tools or open licences. This means the organisation’s approach to open access typically proceeds on an individual project or output basis. Outside of that limited project, the organisation’s default approach is to assert copyright and to either retain all rights (e.g., © Organisation Name) or apply closed licences that prohibit commercial use and modification (e.g., CC BY-NC or CC BY-ND).
Defined List of Machine Readable Statements
Licences, Labels, and Tools that are machine readable present information in a structured format that can be accessed and used by computers.
If an organisation does not use machine readable statements, they typically use non-machine readable descriptors to describe the rights status or terms of release, such as “public domain” or “open content.” These generic, bespoke, or non-standard descriptors indicate the materials are not restricted by copyright or have been published under reuse terms that align with the open definition.
The Survey assigns ‘Other’ when the materials are released using such non-machine readable descriptors, because they are neither standardised nor legally reliable.
Machine Readable Statements
| Statement | Public domain | Copyright disclaimer | Open licence |
|---|---|---|---|
| Creative Commons | |||
| RightsStatements.org |
|
No Known Copyright (NKC) | |
| Open Knowledge Foundation (primarily for databases or open data) | |||
| National Licences | |||
| Other (i.e., bespoke or descriptive statements) | Public domain, Public Domain High Resolution, Free access and use, No copyright | No known copyright restrictions | Open Access, Open Use, Public Domain (with conditions) |
Compliance
Compliance refers to the primary statement about rights and licences used to publish open data and enables sorting according to the desired level of risk. An organisation’s approach is assigned to one of three categories.
Approaches to Compliance
| Category | Copyright | Risk Outcome | Examples |
|---|---|---|---|
| Public domain | No | No risk. No new rights are asserted. Digital surrogates and metadata are in the public domain. | |
| Disclaimer | No | Low risk. No new rights or public domain assertions are made. The onus is on the user to ensure their reuse is legally compliant. |
|
| Open | Yes | No risk if the licence terms are met. New rights are asserted and the licence aligns with international definitions of “open.” |
|